Subscribe to our newsletter
Dimensions: The What, The How and a Personal Take on The Why
I was honoured to be invited to the first future labs meeting at Charleston Library Conference last November. If you’ve never been to a future lab, it’s a brainstorming session where a group of experienced professionals (in this case librarians with a few publishers and vendors sprinkled in) come up with their predictions of how their industry is going to change, often with a technology focus.
I promise I did not bring the topic up. I think it was Michael Levine-Clark, the Associate Dean for scholarly communication and collections services from the University of Denver and the first person asked for a word, who said ‘discovery’. In the back of my mind, I thought, ‘funny you should mention that’.
This has been a big week for Digital Science. Last Monday saw the launch of a major new product; Dimensions. By now, you may have heard a few things about our newest addition to the portfolio. We had a launch party at the Wellcome Trust building in London and it’s been covered in a variety of outlets, including Inside Higher Ed, The Bookseller and the Scholarly Kitchen.
In some ways, Dimensions is different to the other products in our portfolio. To be clear, the product does not mark a change in direction. We maintain our customer-centric, community-driven ethos and commitment to supporting the research lifecycle at every stage. We also continue to work with all stakeholders including publishers, research managers, librarians, funders, and of course, researchers because we recognize the unique value that each facet of the broader community brings. What’s different about Dimensions is that it represents our first major collaborative product built on the deep relationships and commonality of purpose between our existing portfolio of companies and products.
What is Dimensions?
Dimensions is a new type of knowledge discovery product that links publications, grants, patents, and clinical trials with a highly curated and strongly normalized data frame. If you take a look at the free version of the application here, at first glance, it looks like an abstract and indexing service with almost 90 million publications in it. That’s just the beginning, however.
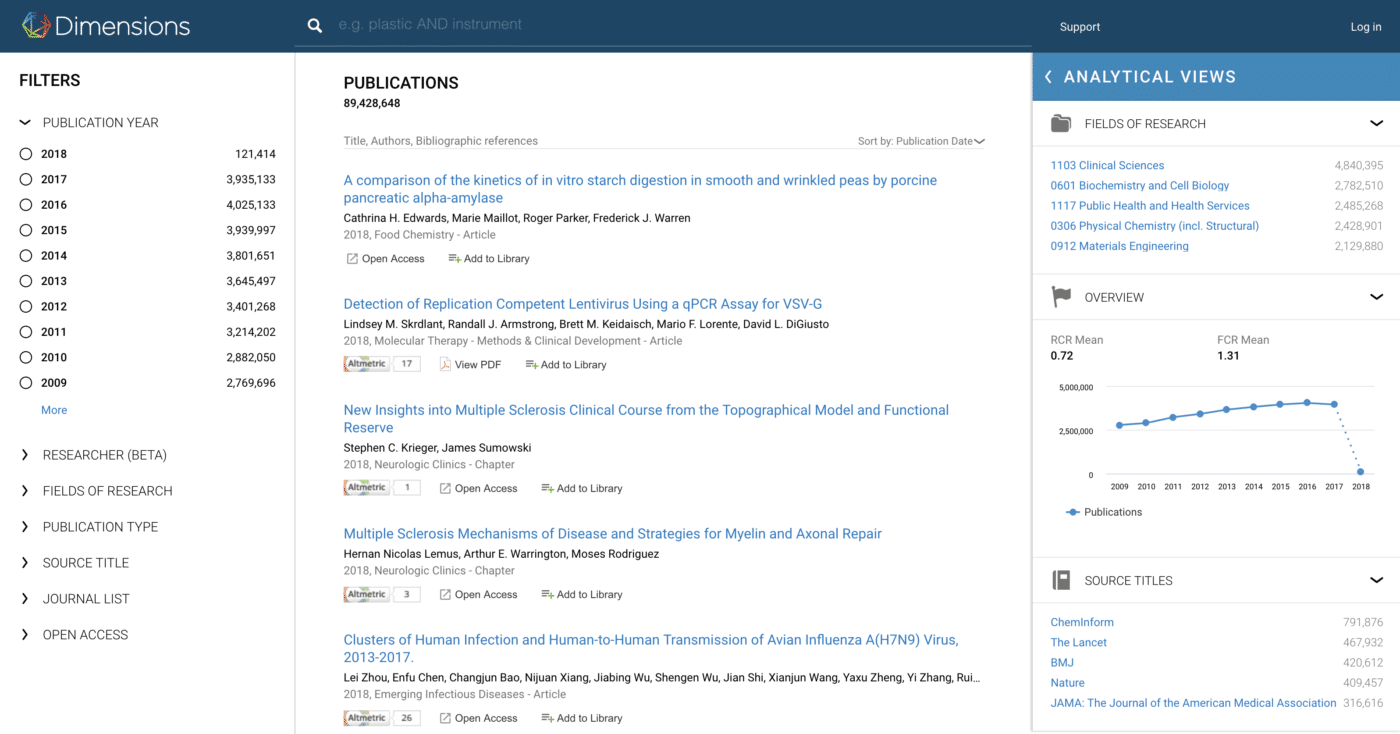
The metadata that we’ve used to create the database has come from a number of sources including but not limited to Crossref, PubMed, a variety of open metadata and abstract services, and our relationships with scholarly publishers. If you look at the left-hand panel, you’ll see that we’ve integrated, curated and cleaned the data in such a way that you can slice and dice in sophisticated ways. For example, affiliation data (which often comes from free text fields in submission systems) has been normalised using GRID (which we made available originally under CC-BY licence in 2015 and later under CC0, so you can download it and use it yourself). We’ve deduplicated authors to enable effective search by researcher, which will be extended with ORCID integration in the next few weeks. We’ve also applied the Australian and New Zealand Standard Research Classification (ANZSRC) Fields of Research (FoR) taxonomy non-exclusively to enable filtering by discipline. Those are just three examples of how we’ve cleaned the data.
There’s a metrics and analytic component to Dimensions. You can see that we’ve added Altmetric and citation data to the search results and if you click on a document that has either citations or altmetric mentions, you can follow those links. In addition, the expandable panel on the right shows the free components of the extensive analytical suite that we’ve developed.
I’ll resist the temptation to give you a run through of the premium versions of Dimensions, there’s a lot of information on the product page here including reports on what’s in the data and what some of the use cases the data have.
Having said that, just to give you a sense of the scope of what we’ve built, here are a few examples. We’ve curated and cross-linked awarded grants from the original Dimension for funders product by ÜberResearch with patent data from IFI Claims and obviously the publications database that I wrote about above is in there. We also have a much larger suite of powerful analytics that enable users to truly understand what’s happening in a research field, compare institutions, researchers, funders, disciplines in a variety of ways.
So what’s in it for me?
I’m so glad that you asked.
For Researchers
If you’re a researcher, we hope it’s fairly obvious. Dimensions is designed to create a discovery platform that is both incredibly simple to use, with as small a barrier to entry as Google or, dare I type, sci-hub, and yet allow for sophisticated literature search strategies such as faceted search, and citation/reference walking. The system aims not only to show you a research result (although it does do that, connecting you to the content in the fewest clicks), it is intended to help you contextualise your search results so that you can see a bigger picture.
While we’re on the subject of big pictures- along with those ~90 million abstracts in the free version, there are almost 3.7 million awarded grants, more than 34 million patents, and over 380 thousand clinical trials, should your institution choose to subscribe to the premium version of Dimensions. You’ll also notice that the pipeline from discovery to download is less convoluted than other discovery solutions. There will be far fewer instances of having to search in one place and then go to another website to download.
For Institutions
For Institutions, not only is Dimensions a new breed of discovery tool for libraries, students and researchers, it’s also a powerful analytics tool to inform strategic decision making. In our talks with research administrators at many institutions, including our development partners, the use cases that have come up have been around identifying strategic partnership possibilities, comparison and benchmarking. Dimensions can help identify emerging fields and leaders in those fields to either collaborate with or even recruit.
For Publishers
Publishers are a critical part of the scholarly communication landscape and much of the infrastructure on which Dimensions relies was funded or built by publishers. Publishers stand to benefit from this in two ways. Firstly, Dimensions’ powerful analytic suite can help publishers identify rising stars in academia who are the authors of today and the editorial board members and editors in chief of tomorrow. It also gives valuable insight into not only what research has been done (publications) and has had impact (citations and Altmetric), but also what is being done (grants). The well-funded research of today becomes the exciting articles of the next couple of years and the citations of five to eight years time. This unique look into the future of which fields, researchers, and institutions will result in the articles, journals and impact of the future is incredibly valuable.
So what’s the second way? Many publishers have been partnering with Digital Science for years to ensure that metadata is complete and accurate. These collaborations aid researcher discovery of their content in the ReadCube environment. Now with Dimensions, we’re taking that discoverability partnership to the next level with the faceted and contextual search approaches in both the free and premium versions. We not only provide researchers with a search result, but we also populate citation and reference links, related articles, grants, clinical trials and patents.
Perhaps most importantly for publishers, we also provide direct links to the version of record. In other words, do you remember that thing I wrote above about a lower barrier to entry for discovery and downlod than sci-hub? Well, that’s one thing that Dimensions does, it helps researchers discover your content quickly and then get it directly from you.
What will Dimensions achieve?
Dimensions launched just last week and there’s an awful lot of excitement about it. We’re receiving huge amounts of feedback from both new users and our existing development partners. We’re committed to being responsive and will continue to add data, refine use cases and support both paying clients and community users.
Earlier this week, Daniel Hook and Christian Herzog wrote an excellent blog post that explored our broader aims for Dimensions as an organization. I won’t reiterate what they wrote, instead, I’m going to mention a personal hope I have for the product.
I’d like Dimensions to reinvigorate the discussion around scholarly content discovery. At some point along the way, we’ve lost our connection with how researchers find and acquire content. As a result, workflows have become clunky and even broken down entirely, causing many researchers to look outside of the publisher-library ecosystem for their needs.
I think that’s at least part of what Michael Levine Clark was alluding to back in Charleston. There’s a real need to reconnect our end-users to scholarly content in ways that add the maximum value and minimise the friction. It’s vitally important to do so, or we’ll continue to see researchers circumventing the services we provide in order to find content through easier ways.