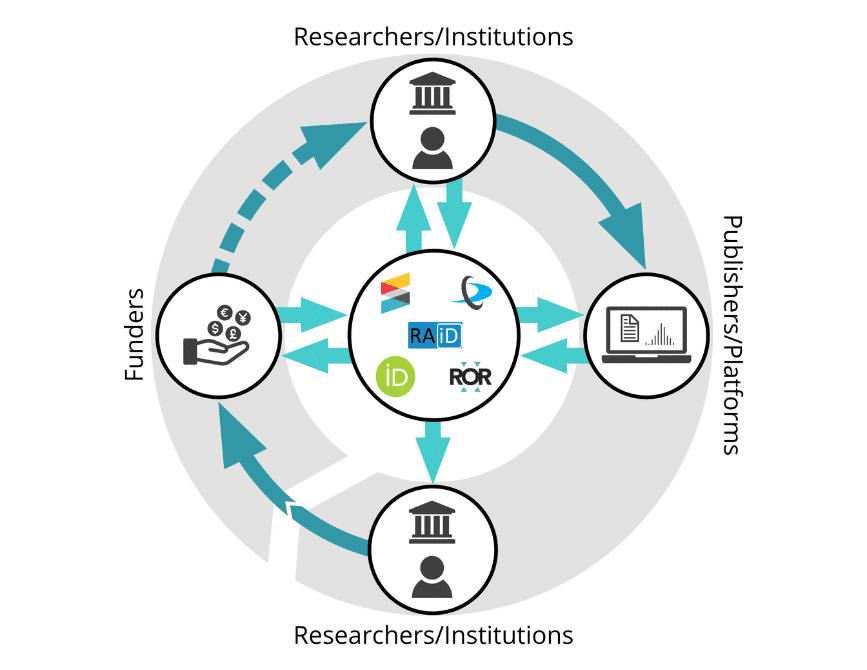
Persistent identifiers – or PIDs – are long-lasting references to digital resources.
In other words, they are a unique label to an entity: a person, place, or thing. PIDs work by redirecting the user to the online resource, even if the location of that resource changes. They also have associated metadata which contains information about the entity and also provide links to other PIDs. For example, many scholars already populate their ORCID records, linking themselves to their research outputs through Crossref and DataCite DOIs. As the PID ecosystem matures, to include PIDs for grants (Crossref grant IDs), projects (RAiD), and organisations (ROR), the connections between PIDs form a graph that describes the research landscape. In this post, Phill Jones talks about the work that the MoreBrains cooperative has been doing to show the value of a connected PID-based infrastructure.
Over the past year or so, we at MoreBrains have been working with a number of national-level research supporting organisations to develop national persistent identifier (PID) strategies: Jisc in the UK; the Australian Research Data Commons (ARDC) and Australian Access Federation (AAF) in Australia; and the Canadian Research Knowledge Network CRKN, Digital Research Alliance of Canada (DRAC), and Canadian Persistent Identifier Advisory Committee (CPIDAC) in Canada. In all three cases, we’ve been investigating the value of developing PID-based research infrastructures, and using data from various sources, including Dimensions, to quantify that value. In our most recent analysis, we found that investing in five priority PIDs could save the Australian research sector as much as 38,000 person days of work per year, equivalent to $24 million (AUD), purely in direct time savings from rekeying of information into institutional research management systems.
Investing in infrastructure makes a lot of sense, whether you’re building roads, railways, or research infrastructure. But wise investors also want evidence that their investment is worthwhile – that the infrastructure is needed, that it will be used, and, ideally, that there will be a return of some kind on their investment. Sometimes, all of this is easy to measure; sometimes, it’s not.
In the case of PID infrastructure, there has long been a sense that investment would be worthwhile. In 2018, in his advice to the UK government, Adam Tickell recommended:
Jisc to lead on selecting and promoting a range of unique identifiers, including ORCID, in collaboration with sector leaders with relevant partner organisations
More recently, in Australia, the Minister for Education, Jason Clare, wrote a letter of expectations to the Australian Research Council in which he stated:
Streamlining the processes undertaken during National Competitive Grant Program funding rounds must be a high priority for the ARC… I ask that the ARC identify ways to minimise administrative burden on researchers
In the same letter, Minister Clare even suggested that preparations for the 2023 ERA be discontinued until a plan to make the process easier has been developed. While he didn’t explicitly mention PIDs in the letter, organisations like ARDC, AAF, and ARC see persistent identifiers as a big part of the solution to this problem.
A problem of chickens and eggs?
With all the modern information technology available to us it seems strange that, in 2022, we’re still hearing calls to develop basic research management infrastructure. Why hasn’t it already been developed? Part of the problem is that very little work has been done to quantify the value of research infrastructure in general, or PID-based infrastructure in particular. Organisations like Crossref, Datacite, and ORCID are clear success stories but, other than some notable exceptions like this, not much has been done to make the benefits of investment clear at a policy level – until now.

It’s very difficult to analyse the costs and benefits of PID adoption without being able to easily measure what’s happening in the scholarly ecosystem. So, in these recent analyses that we were commissioned to do, we asked questions like:
- How many research grants were awarded to institutions within a given country?
- How many articles have been published based on work funded by those grants?
- What proportion of researchers within a given country have ORCID IDs?
- How many research projects are active at any given time?
All these questions proved challenging to answer because, fundamentally, it’s extremely difficult to quantify the scale of research activity and the connections between research entities in the absence of universally adopted PIDs. In other words, we need a well-developed network of PIDs in order to easily quantify the benefits of investing in PIDs in the first place! (see Figure 1.)
Luckily, the story doesn’t end there. Thanks to data donated by Digital Science, and other organisations including ORCID, Crossref, Jisc, ARDC, AAF, and several research institutions in the UK, Canada, and Australia, we were able to piece together estimates for many of our calculations.
Take, for example, the Digital Science Dimensions database, which provided us with the data we needed for our Australian and UK use cases. It uses advanced computation and sophisticated machine learning approaches to build a graph of research entities like people, grants, publications, outputs, institutions etc. While other similar graphs exist, some of which are open and free to use – for example, the DataCite PID graph (accessed through DataCite commons), OpenAlex, and the ResearchGraph foundation – the Dimensions graph is the most complete and accessible so far. It enabled us to estimate total research activity in both the UK and Australia.

However, all our estimates are… estimates, because they involve making an automated best guess of the connections between research entities, where those connections are not already explicit. If the metadata associated with PIDs were complete and freely available in central PID registries, we could easily and accurately answer questions like ‘How many active researchers are there in a given country?’ or ‘How many research articles were based on funding from a specific funder or grant program?’
The five priority PIDs
As a starting point towards making these types of questions easy to answer, we recommend that policy-makers work with funders, institutions, publishers, PID organisations, and other key stakeholders around the world to support the adoption of five priority PIDs:
- DOIs for funding grants
- DOIs for outputs (eg publications, datasets, etc)
- ORCIDs for people
- RAiDs for projects
- ROR for research-performing organisations
We prioritised these PIDs based on research done in 2019, sponsored by Jisc and in response to the Tickell report, to identify the key PIDs needed to support open access workflows in institutions. Since then, thousands of hours of research and validation across a range of countries and research ecosystems have verified that these PIDs are critical not just for open access but also for improving research workflows in general.
Going beyond administrative time savings
In our work, we have focused on direct savings from a reduction in administrative burden because those benefits are the most easily quantifiable; they’re easiest for both researchers and research administrators to relate to, and they align with established policy aims. However, the actual benefits of investing in PID-based infrastructure are likely far greater.
Evidence given to the UK House of Commons Science and Technology Committee in 2017 stated that every £1 spent on Research and Innovation in the UK results in a total benefit of £7 to the UK economy. The same is likely to be true for other countries, so the benefit to national industrial strategies of increased efficiency in research are potentially huge.
Going a step further, the universal adoption of the five priority PIDs would also enable institutions, companies, funders, and governments to make much better research strategy decisions. At the moment, bibliometric and scientometric analyses to support research strategy decisions are expensive and time-consuming; they rely on piecing together information based on incomplete evidence. By using PIDs for entities like grants, outputs, people, projects, and institutions, and ensuring that the associated metadata links to other PIDs, it’s possible to answer strategically relevant questions by simply extracting and combining data from PID registries.
Final thoughts
According to UNESCO, global spending on R&D has reached US$1.7 trillion per year, and with commitments from countries to address the UN sustainable development goals, that figure is set to increase. Given the size of that investment and the urgency of the problems we face, building and maintaining the research infrastructure makes sound sense. It will enable us to track, account for, and make good strategic decisions about how that money is being spent.
About the Author

Phill Jones
Co-founder, Digital and Technology | MoreBrains Cooperative
Phill is a product innovator, business strategist, and highly qualified research scientist. He is a co-founder of the MoreBrains Cooperative, a consultancy working at the forefront of scholarly infrastructure, and research dissemination. Phill has been the CTO at Emerald Publishing, Director of Publishing Innovation at Digital Science and the Editorial Director at JoVE. In a previous career, he was a bio-physicist at Harvard Medical School and holds a PhD in Physics from Imperial College, London.
The MoreBrains Cooperative is a team of consultants that specialise in and share the values of open research with a focus on scholarly communications, and research information management, policy, and infrastructures. They work with funders, national research supporting organisations, institutions, publishers and startups. Examples of their open reports can be found here: morebrains.coop/repository



