Subscribe to our newsletter
Digital Science Hackbreaks: The SureChem Mobile App
Scientific Literature Survey using Machine Vision
Earlier this year, a group of Digital Science engineers decamped to a holiday home in Norfolk for three days of intensive hacking. This blog posting is about one of the applications developed at the Hackbreak: SureChem Mobile, a smartphone application to help chemists learn more about chemical compounds in printed matter. To recognize the compounds in photographs taken on the smartphone, we used a combination of Keymodule’s CLiDE machine vision tool plus several custom image pre-processing steps.
Here’s a video of the prototype SureChem mobile application in action. This first version links out to widely used, general purpose chemistry databases. In a future version we’ll be adding support for the more specialized data available in SureChem patent documents:
SureChemMobile Prototype Demo from Digital Science on Vimeo.
The aim of the application is to provide a new workflow for scientific survey:
- Use a mobile phone camera to take a photograph of a chemical structure
- Upload the picture to the SureChem server for image processing and analysis
- After successful recognition, retrieve resulting data from the server, including the Molfile and SMILES representation of the chemical structure, and chemical meta-data such as a generated name.
- Query external chemistry resources to learn more, such as detailed chemical information from ChemSpider and Journal articles from the Royal Society of Chemistry that refer to the compound
The idea is to make it easier for a researcher to learn more about a compound after seeing it in a publication.
Implementation
The prototype mobile application was created over three days (and nights) in the holiday home shown below, by team J – that is, Jan Wedekind (expert in all things image processing), Jim Siddle (SureChem back end guru), and Jose Airosa (SureChem API master).
We used the PhoneGap toolkit to develop the mobile app, and a Sinatra server application was used to receive the queries and return the results via a RESTful API. Incoming images were preprocessed using the HornetsEye Ruby library and conversion of the chemical image to a searchable chemical structure was performed using Keymodule’s CLiDE. Chemical meta-data was generated using the ChemAxon JChemBase toolkit.

Below, we’ve included a series of images that together describe the preprocessing algorithm that identifies and isolates a chemical compound in an image. This algorithm is applied to images before they are passed to CLiDE for chemical recognition.
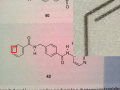 |
The initial image. An enlarged version of the area marked by the red rectangle is shown in the top-right corner of the image. |
 |
A dilated version of the input image. This is used as an estimate of the local background brightness. |
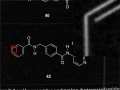 |
The difference of the (greyscale) input image and the dilated image serves as a basis for thresholding. |
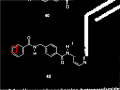 |
Otsu’s method is used to reduce the data to a binary image. |
 |
The input image is dilated and the connected components are identified. |
 |
A weighted histogram is used to find a large component close to the centre of the image. |
 |
The selected component of the dilated binary image and the initial binary image are used to extract the graphical representation of the chemical structure. |
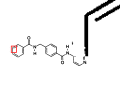 |
The result is ready to be processed with optical structure recognition software. |
Here’s a larger version of the input photograph, side-by-side with the image we pass for chemical recognition.
That’s all for now, but keep an eye out for future articles where we’ll describe other experiments and prototypes from Digital Science hackbreaks.