
Researchers
Findable, Accessible, Interoperable and Reusable (FAIR) data has become an aim for a large proportion of academic funders globally. This has happened in the 7 years since the publication of ‘The FAIR Guiding Principles for scientific data management and stewardship’. Encouraging or mandating Open and FAIR data is the most obvious return on investment (ROI) improvement in academic publishing. Academic funders invest substantial resources in research projects. By promoting the FAIR data principles, they aim to maximise the return on their investments by ensuring that the data generated from funded research can be fully utilised and have a broader impact beyond the original project.
But who else is benefiting from FAIR data? This is part one of a three-part series that aims to highlight the author’s thoughts on when different sectors/players will benefit from Open FAIR data. In this instalment, we delve into how researchers are the primary beneficiaries, despite shouldering the responsibility of publishing FAIR data.
By adhering to FAIR principles, researchers can make their data findable and accessible to the broader scientific community. This increased visibility enhances collaboration opportunities, fosters interdisciplinary research, and paves the way for novel discoveries. The interoperability aspect of FAIR data allows researchers to combine datasets from diverse sources, facilitating new insights and innovative approaches to problem-solving.
The burden of publishing FAIR data currently lies primarily with the researchers themselves, adding an extra layer of effort to an already demanding research process. However, collaborative efforts among stakeholders, including academic institutions, publishers, and infrastructure providers, can alleviate this burden and streamline the FAIR data publication process. Supporting researchers with appropriate resources, tools, and incentives will help foster a culture of data sharing and enhance the adoption of FAIR data practices.
70% of researchers responding to our State of Open Data Survey are required to make their data openly available. As the publication of open research data moves from a ‘nice to have’ to a core part of the academic literature, the academic community needs to follow an achievable roadmap to make data useful and subsequently research more efficient.
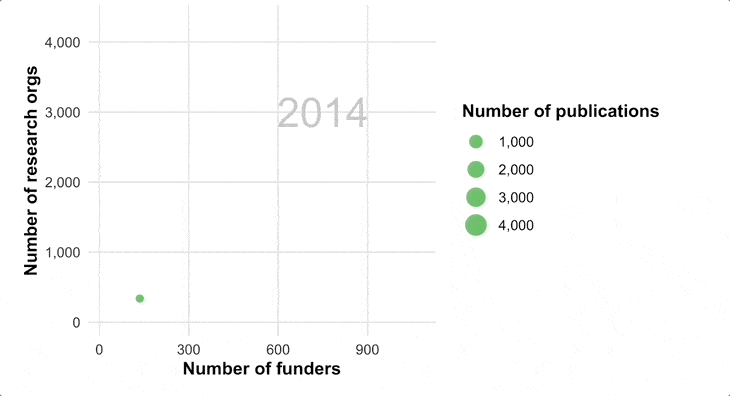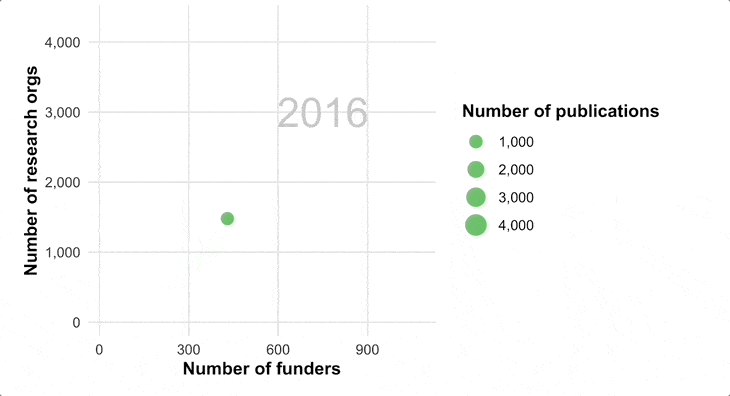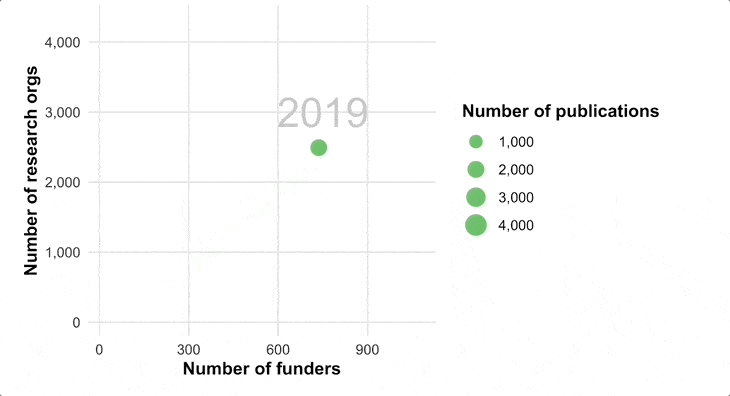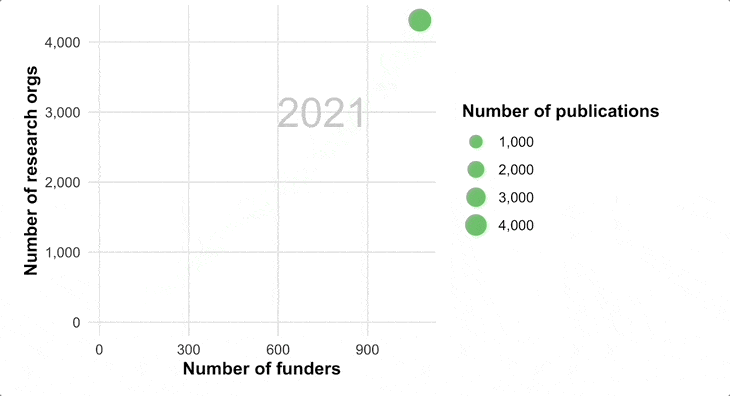
We are optimistic of a future state world, where a group of researchers generates new information based on new hypotheses, and makes it available on Figshare (or any other open repository) for others to then pull together the combined world’s knowledge to look for new patterns and discoveries that the original authors had not thought to look for.
This is already happening — with the tracking of citations and Altmetrics on item pages, users can see who is mentioning and reusing their data and the progression that has had on scientific advancement. For example, take this use case of a University of Sheffield researcher who made his data available on Figshare and has since developed collaborations and new lines of enquiry into adjacent areas of research. Deepmind’s Alphafold has recently demonstrated the power of well-curated, homogenous open data. When thinking of research data, future consumers will not just be human researchers — we also need to feed the machines. This means that computers will need to interpret content with little to no human intervention. For this to be possible, the outputs need to be in machine-readable formats and the metadata needs to be sufficient to describe exactly what the data are and how the data was generated.
Whilst repositories can be responsible for ensuring the machines can access and interpret the content using defined open standards, the quality of the content and metadata, as well as consistency in how data is shared within a field, lies at the feet of the researchers themselves. There is not currently enough support for metadata curation at the generalist repository level, but this does not mean that poorly described data is not useful to humans and machines.
There is a home for every dataset
1. Ideally each subject would have a subject-specific data repository with custom metadata capture and a subject specialist to curate the data. If there is a subject-specific repository that is suitable for your datasets, use that one.
2. If there is no subject-specific repository, you should check with your institution’s library as to whether they have a data repository. If they do, they will most likely have a team of data librarians to guide you through your dataset publication.
3. If there is no subject-specific repository, you should upload and publish your data on Figshare.com, or another suitable generalist repository. How to upload and publish your data on Figshare.com
To make open data useful for researchers – some context is needed
Data with no curation can be useful, but they must at least adhere to the following:
- Academic files and metadata are available on the internet in repositories that follow best practice norms.
In order to make data Findable and Accessible (the F and A of FAIR), the metadata should be sufficient to be discoverable through a Google search or available when clicking through from a peer-reviewed publication. We can see that humans are good at finding context around datasets that are not well described as a standalone output. The related paper often has enough context to make the data re-usable by separate research groups. When looking at some of the most cited outputs across Figshare infrastructure, the one with the lightest metadata has the following as a description: “The data comprises phenotypic measurements from two field trials in South Australia and genotyping information for more than 500 diverse wheat accessions.” There is no README file. And yet this has been re-used and cited by another research group.

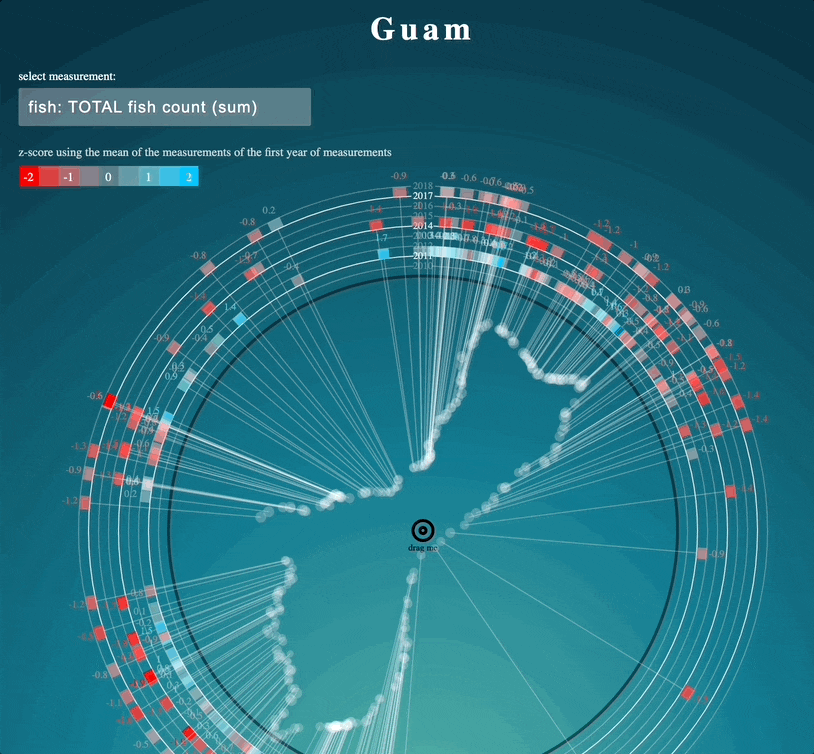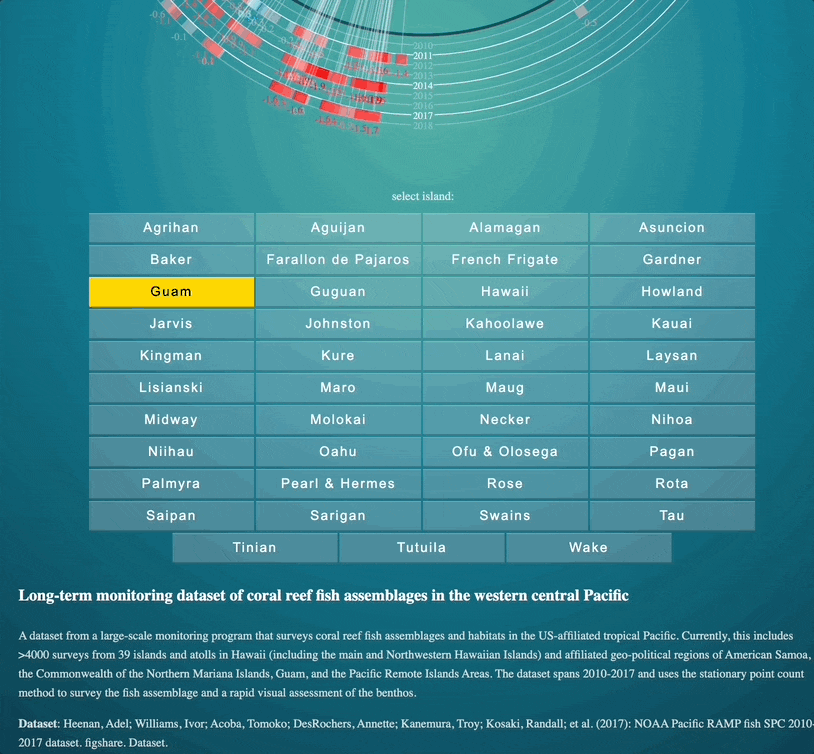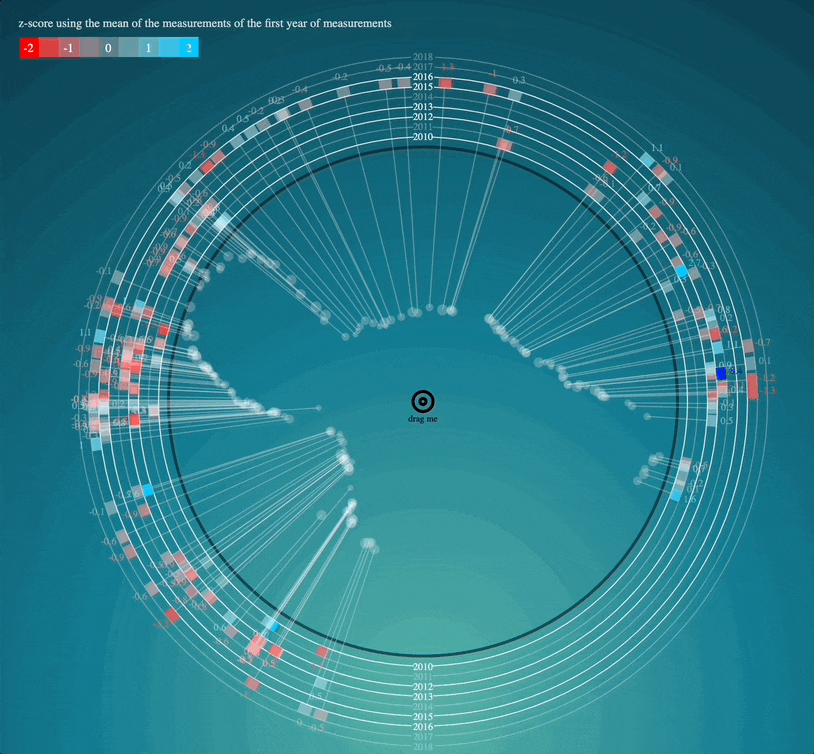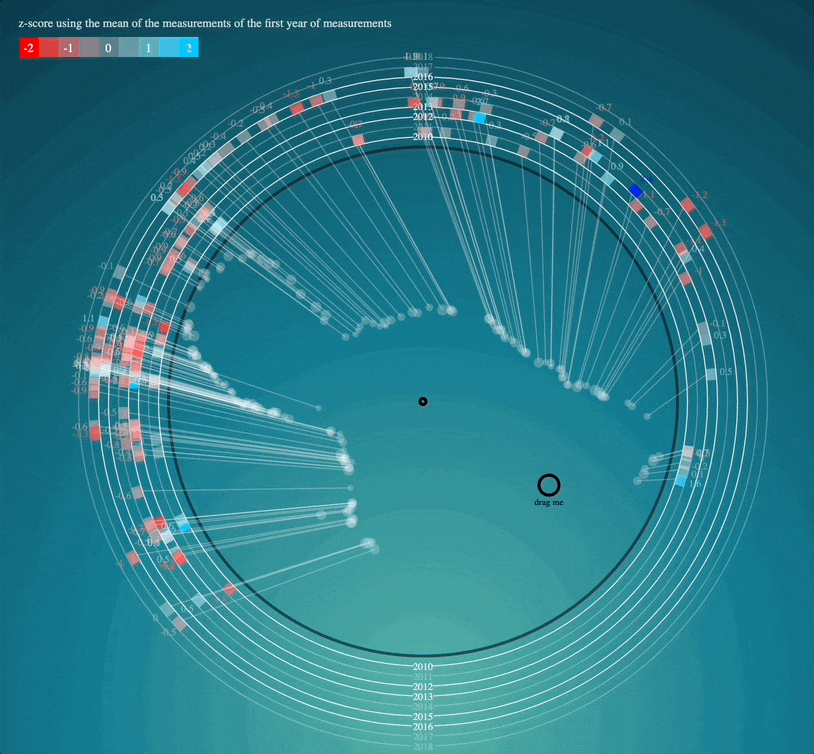
Internally at Figshare, we have previously looked at data associated with publications to see if humans can interpret and re-use the data. To showcase the reusable possibilities with Figshare, we enlisted Jan Tulp, data visualisation expert and founder of Tulp Interactive, to reuse three datasets published in Figshare as part of a publication. The task was to take these three datasets and create visualisations using only the data, the metadata found in the item page, and the original publication.
Whilst the metadata wasn’t fantastically detailed, the associated publication, linked from the landing page on Figshare, allowed Jan to re-interpret the data with a beautiful visualisation, showing fish populations at different sites around islands.
We are also seeing evidence that machines can infer new knowledge from lightly described datasets.
Figshare works with publishers to make outputs that are not the peer-reviewed article citable, previewable and persistent. This is often associated datasets that may be checked by editorial staff at the journal. The vast majority of this content is supplemental data, with varying levels of descriptive metadata and context. Many naysayers suggest this information has no use outside the context of the individual paper however we do see evidence that this information can be re-used at scale, as exemplified by a recent paper, “A resource for automated search and collation of geochemical datasets from journal supplements”:
“Here, we present open-source code to allow for fast automated collection of geochemical and geochronological data from supplementary files of published journal articles using API web scraping of the Figshare repository. Using this method, we generated a dataset of ~150,000 zircon U-Pb, Lu-Hf, REE, and oxygen isotope analyses. This code gives researchers the ability to quickly compile the relevant supplementary material to build their own geochemical database and regularly update it, whether their data of interest be common or niche.”
The authors also propose a set of guidelines for the formatting of supplementary data tables that will allow for published data to be more readily utilised by the community.

Whilst the above examples demonstrate that poorly-described research data can be useful in some situations, it is not something that should be encouraged and merely highlights that open data is better than no data. The research community should be focussed on the principles of open, FAIR data as the biggest potential return on investment for academic funders in the next 50 years – both in the efficiency of research and the discovery of new knowledge.
For researchers, there are two immediate wins by creating and consuming FAIR data. By publishing well-described data, they have an easy route to greater impact of their research. There is also a wealth of information that is available today in open repositories. By becoming an early consumer of this, researchers can get the upper hand on their peers by obtaining a fuller picture of a research field.
By embracing FAIR data, researchers empower themselves and the wider scientific community, enabling the acceleration of knowledge and fostering innovation. In the next two parts of this blog series, we will explore how other sectors and players can harness the power of open, FAIR data. Stay tuned for more insights on this transformative paradigm shift in data management and its implications for various stakeholders.





























