
Reflecting on the growth of Figshare and the future of open data sharing with Mark Hahnel
There’s a good quantity of research that’s been made open that otherwise would not have been made open without Figshare. I’m very proud of that fact.”
On April 13th 2023, Mark tweeted that Figshare had reached seven million outputs, a significant milestone in anyone’s book! He and I jumped on a quick call to discuss what that achievement means for Figshare, and before we knew it our chat had meandered onto what it was like in the very early days of Figshare and Overleaf, and how milestones and celebrations change as the numbers keep going up and to the right! 🙂
We hope you enjoy where the conversation takes us. If you’d also like a more serious analysis to complement our light-hearted discussion, check out Figshare’s report on The State of Open Data 2022.
Mark Hahnel is Figshare’s founder and CEO, and I (John Hammersley) am one of the co-founders of Overleaf. Figshare and Overleaf are both part of Digital Science.
Quick links
- Breakfast
- Seven million outputs
- Incremental gains
- What’s most popular?
- It’s all about neuroscience
- Programmatic downloads via the API
- Inevitability, excitement, and new unknowns
Breakfast
John Hammersley (JH): Well, that looks like a good breakfast.
Mark Hahnel (MH): Mm-hmm. Start with the important things. This video isn’t going live somewhere is it?
JH: No, no. It’s just for my notes. Just to save me typing. Yeah…


JH: Swiftly moving on, onto the amazing stat…seven million outputs on Figshare!
Seven million outputs
MH: Yeah, so I put out the seven million objects tweet as I’m looking at the platform, checking there’s no suspect content and things like that, and it’s a number that rolled over when I looked at it. There’s a good quantity of research that’s been made open that otherwise would not have been made open without Figshare. I’m very proud of that fact.
MH: One clarification I should definitely add upfront though is that this isn’t all content that people have uploaded themselves; we have publishers using Figshare to e.g. make supplementary materials more accessible, and institutions who e.g. upload content from their departments.
JH: We have a similar number on Overleaf — 12 million users — not all still use the platform, but it’s still amazing that there are millions of people who’ve used Overleaf over the years. So even though some of those seven million objects on Figshare have come from publishers and institutions, you started Figshare 11 years ago with your own data — to make your data more available than it just sitting on your hard-drive — and 11 years later there’s now seven million items on this platform you’ve built. That must be an amazing feeling now, but how was it at the start?
We had loads of signups…and then it took three days for somebody to upload something!”
MH: Yeah, it is amazing, and thinking back to year one — I remember, we had people using it, then we rebuilt it from scratch, and the relaunch was featured on TechCrunch. We had loads of signups, and then it took three days for somebody to upload something…so 48 hours in I was sat there…zero people have uploaded anything! What’s going on?! And now we get hundreds or thousands everyday. So that’s a good metric to follow.
MH: We knew people would [upload things], because people had in the past (before the relaunch), but we’d never really checked how often they were doing it. And also, when you completely overhaul the interface….is there a problem, have we broken uploads somehow, or made it completely unintuitive? So it was a relief when those first uploads on the new platform came in.
Incremental gains
JH: I remember when we were on HackerNews very early on — you get this influx of people kicking the tyres. But we always wondered if this was going to translate into anything meaningful. For us (Overleaf) we saw that even though the (usage) line goes back down again after the big spike, it doesn’t go back down to where it was, it’s generally a bit higher up.
Update: I dug out this old graph we produced in April 2014 where we marked the times we were featured on HN and Slashdot. Although activity clearly drops after the spike, we retained some of those users and it helped give us an overall boost in how quickly we doubled, tripled, quadrupled in size:

MH: Incremental bumps!
JH: Indeed…which turn into incremental gains! And now, hundreds of thousands of users on Overleaf and hundreds of thousands of outputs shared every day (on average) on Figshare… it’s mind-blowing.
What’s most popular?
JH: Do you happen to know offhand what the most…I would say popular, but maybe it’s simpler to say viewed, or downloaded, thing is?
MH: Yeah, there are few ways to measure it right (popularity). When it comes to most cited outputs <begin product pitch> we’re the only repository that allows you to track citations for all of your research outputs <end product pitch>. Of the most cited outputs, four out of the top ten are software. Even though we only have 10,000 software outputs (out of seven million in total) across all of Figshare.
JH: Wow, that’s cool, do you know what the software is?
MH: I can definitely find that out (see below)! I should caveat that last stat is of end user uploaded content – so someone has needed to find a place for it, and has posted it to Figshare.
Update: Mark shared the link to the graph-tool python library after the call, and also this post from a few years ago which examines the top 100 cited outputs on Figshare. It looks at commonalities across those software objects that were regularly cited, such as the presence of README files and a lot of metadata.
It’s all about neuroscience
MH: The most popular subject is neuroscience…which is interesting because there’s all these other repositories for neuroscience. So there’s loads of places to put neuroscience data, there’s not loads of places where I can put *insert random subject x* data. So surely those need a place to be … and I think it’s more the culture; neuroscientists are used to sharing all their data, and so when they have files they don’t have a home for, they still share them.
JH (smiling): We always knew when we had a neuroscientist on Overleaf, because our dictionary wasn’t very good, and if you wrote “neuroscience”, it thought it was a misspelling, and the suggestion it gave was “pseudoscience”, as the correction, and so we used to get people tweeting “are you trying to tell me something Overleaf?” or “what has Overleaf got against neuroscience?” 🙂
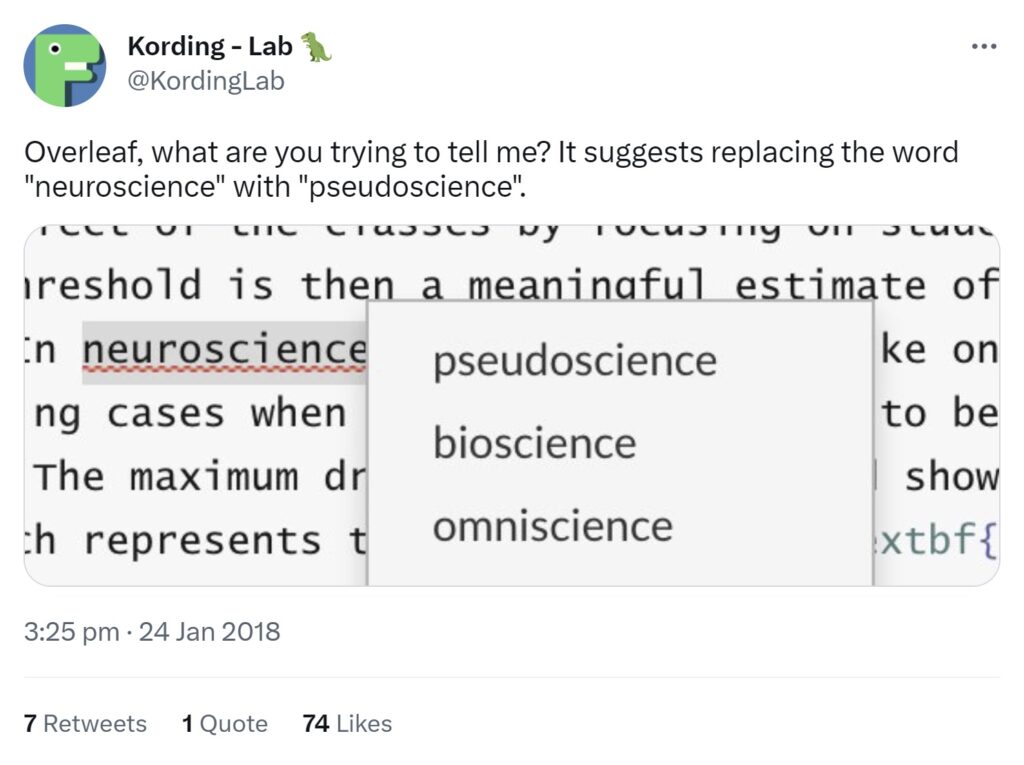
MH: That’s brilliant. It’s hard to please all the people all the time!
Programmatic downloads via the API
MH: The most downloaded data, which is kind of cool and zeitgeisty right now, is large data sets for AI / machine learning models…for example, there’s a database of faces which gets downloaded a lot, presumably for facial recognition.
MH: And the reason they’re the most downloaded is because they’re programmatically downloaded…it’s not someone finding it and pushing download, it’s someone using the API and using it in a query of some compute they’re doing somewhere.
JH: Do you find the API gets much use? Would you say most downloads are through the API?
MH: It definitely gets some use, but as for the most downloads…I don’t know that, but I’d suggest probably no….if it is it’ll be because these random one-off datasets are getting a million downloads versus everyone else getting say 10…so there might be a really big skew.
MH: I think people tend to build tools that push content into Figshare, rather than build tools to interact with it. This is actually a bit of a flaw in the product at the moment — if you build things to interact with it, because there’s such heterogeneity in the file types, you can’t programmatically query a file — you can’t say “look at that file, and tell me what’s in column C Row 3 – you have to download it and parse it on your end. So less people do that because there’s that extra step.
JH: I see, and you’re right that that probably skews the download stats a bit as well, because if you need to use stuff (i.e. if you want to parse it programmatically), you have to download it all first. I look forward to the upgraded API allowing querying of files without downloading 🙂
MH: No promises!
Inevitability, excitement, and new unknowns
JH: So, back to seven million objects…when you saw that number tick over, what did it feel like?
MH: Good question! There was definitely a lot of pride, but it wasn’t like the early days when we hit milestones…probably because I was expecting it (even though I wasn’t explicitly tracking it).
JH: Makes sense — I remember back when John and I did the Overleaf founder story video (back in 2015), we had one or two hundred thousand users…which felt massive at the time (and it was!), but there was something more than that. The growth at that stage still felt very…unexpected.
MH: Whereas now it’s predictable, right? I see Overleaf has just hit 12 million users, and I bet you could predict to within a few weeks when you’ll hit 13 million. So whilst it’s still something to celebrate, it’s not quite the same.
JH: Yeah, you’re right, and I expect it’s the same for Figshare? Like in the early days, in that first 48 hours, you had a real concern as to whether anyone was going to upload anything. And then you get to 10 uploads, a hundred, a thousand and you still don’t know if it’s going to last. You didn’t know if you’re going to get to 10,000 uploads, you didn’t know if you’re going to get to a hundred thousand…
MH: Yeah, exactly — if you asked me back then, if you asked me in those first 48 hours “would we ever get to 10 million outputs across all Figshare infrastructure?” I’d say “Well, I have no idea, that’s too far ahead. Can you imagine 10 million outputs?” And now I’m like, yeah, very confident (touchwood!) it’s going to happen, even though it’s still three million more.
…you know we might look back on seven million, and think ‘wow, those were the slow days!’”
JH: So I have to ask — what is exciting now? 🙂
MH: The excitement is still in the volume, just in a different way. I think the exciting thing for me is that this is still the start. If you said to me in 10 years, is there going to be less data publishing or more data publishing than there is today, there’s definitely going to be more. So, the volume, you know, we might look back on seven million, and think “wow, those were the slow days!”
MH: Let’s assume there’s something like three million papers a year that get published. So if you assume three million papers, then how many data sets are associated with each paper? Let’s average four. You’re looking at 12 million data sets and that’s just data sets. What about the code? What about the posters? What about the …? So I think there will be a saturation point, but we’re nowhere near the saturation point, and that is exciting. The inevitability is exciting because of the growth that’s still ahead.
JH: And so just to flip that around a bit for the last question: the worry in the early days was that no-one uses this, no-one uploads any content, and everything just fizzles out. Now there isn’t that particular worry — as you say, the content volume is more predictable. So what’s the worry that’s replaced it? What keeps you up at night these days?
MH: The worries have definitely changed, and it wasn’t just content worries — we also worried whether storage capacities keep up, will the cost of storage keep coming down? But that did continue, as did the uploads, and so there’s going to be more data, the world has more data, and we can scale to handle it. That’s no problem.
MH: So the concern for me is the trust part, the research integrity part. We’ve got all of this information. How do we curate it to make it useful and be meaningful? There’s lots of ideas on how to solve that problem, and lots of smart people working on it (step forward Leslie!), but that’s definitely something that’s often on my mind.
If you’ve enjoyed reading this article and would like to chat to us about your experience as a start-up founder, or other interesting topic, please let us know — we’re always happy to hear your ideas and suggestions! Or just ping me on Twitter / LinkedIn 🙂



